Using Jupyter notebook to manage your BigQuery analytics
in Blog
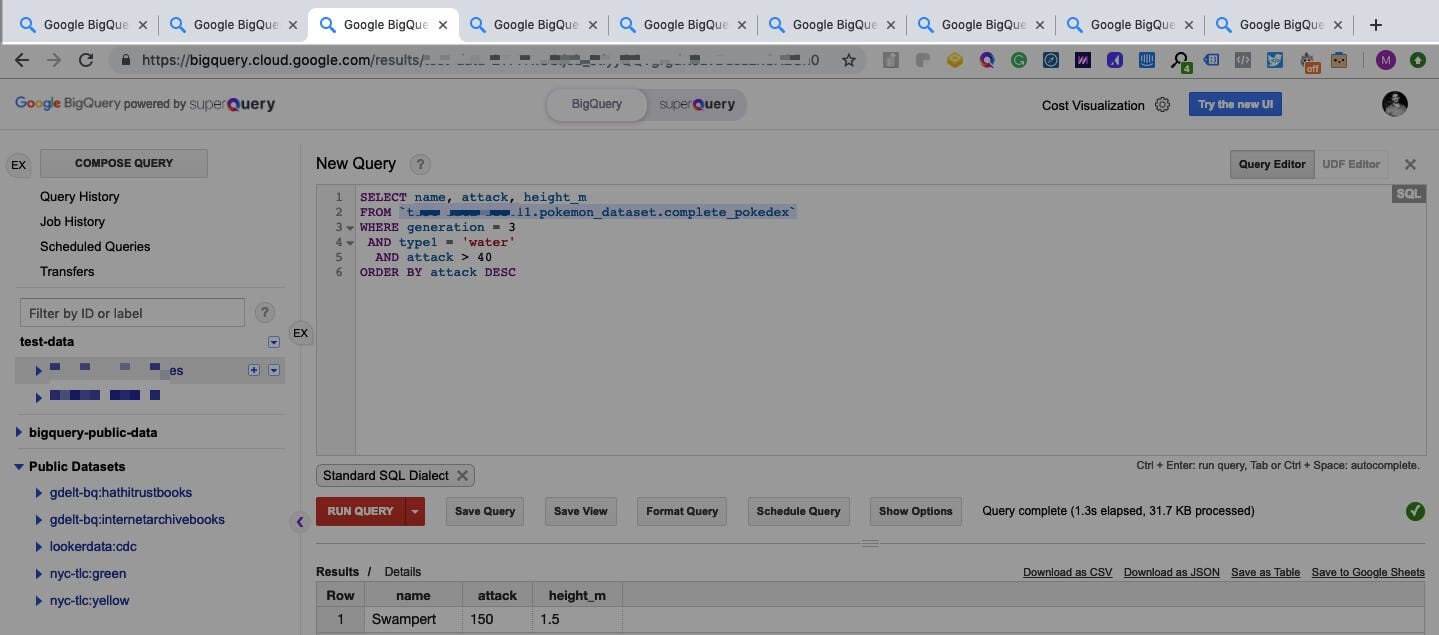
How to utilize Jupyter Notebook to manage your SQL queries better.
If you have the struggle of opening and continuously switching between ten thousand BigQuery tabs, you are not alone. As a data professional, working with SQL queries is a daily task, and if you are not organized, you will quickly drown yourself in Chrome tabs.
Fortunately, you can use Jupyter notebooks with several packages to have a much more pleasant experience dealing with SQL queries. In this post, I will go over the steps to set up the environment and move your workflow to Jupyter notebooks. Whether you are a Data Analyst, Data Engineer, or Data Scientist, having an organized workflow will help boost your productivity significantly.
Environment setup
Download and Install Anaconda
The quickest and easiest way to install Python and Jupyter Notebook is to use the Anaconda Distribution. You can follow the instructions here to find the guide to installing Anaconda on your operating system.
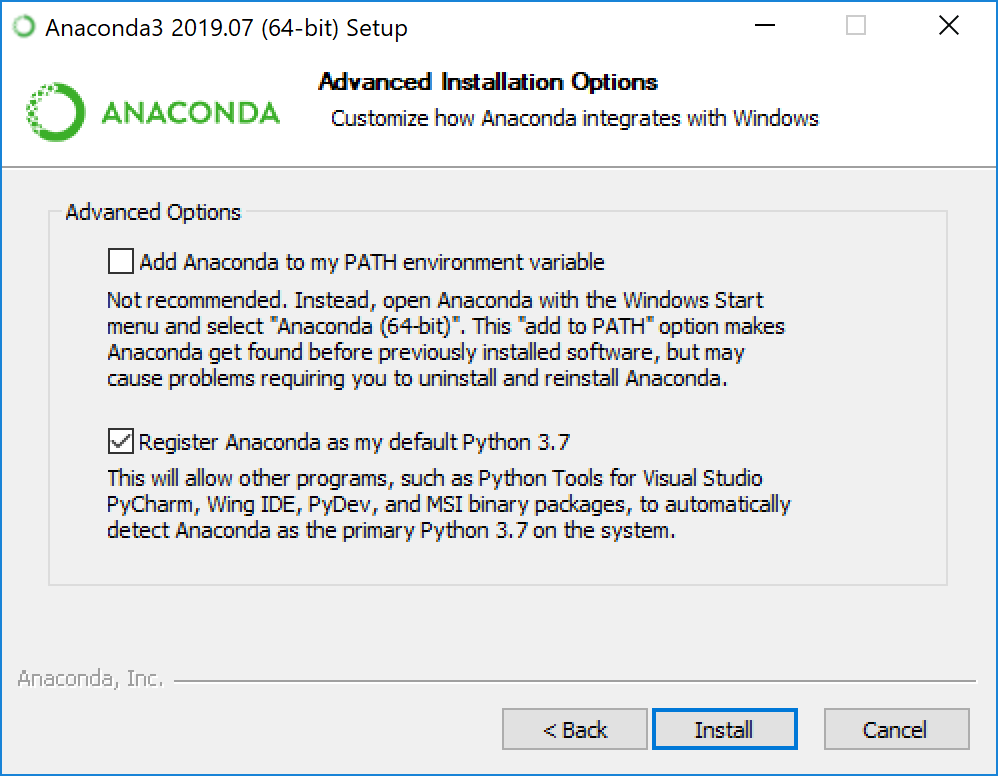 Make sure you add Anaconda to the PATH environment variable.
Make sure you add Anaconda to the PATH environment variable.
Install Google Cloud Python SDK and authenticate
Follow Google’s guide to install Cloud SDK for your specific OS. After installing and initialize the SDK, you should setup application-default authentication by doing the following:
Open Terminal/Anaconda prompt/Command line and type in the following
gcloud auth application-default login
A browser will pop up, asking you to login with your Google account. Sign in and select Allow to authenticate the Cloud SDK.
Install GCP python library and pandas_gbq
You are encouraged to set up a separate environment per project to install python packages. For the sake of simplicity, I will skip the steps to create a different environment here.
Install the following Python packages:
pip install --user --upgrade google-api-python-client
pip install --user pandas-gbq -U
SQL queries in Jupyter Notebook
Open Jupyter Notebook or Jupyter Lab
You can quickly launch a Jupyter Notebook or Jupyter Lab instance from the command line using either of the following:
jupyter notebook
jupyter lab
Create a Python 3 notebook and make sure you select the environment in which you installed your packages earlier.

Import libraries
import pandas as pd
import pandas_gbq
from google.cloud import bigquery
%load_ext google.cloud.bigquery
# Set your default project here
pandas_gbq.context.project = 'bigquery-public-data'
pandas_gbq.context.dialect = 'standard'
Import the required library, and you are done! No more endless Chrome tabs, now you can organize your queries in your notebooks with many advantages over the default editor. Let’s go over some examples.
In cell queries
With the %%bigquery magic, you can write multi-line in-cell queries as follow:
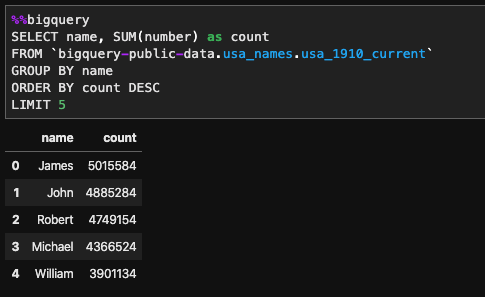
You can also store the result to a pandas data frame using %%bigquery df_name
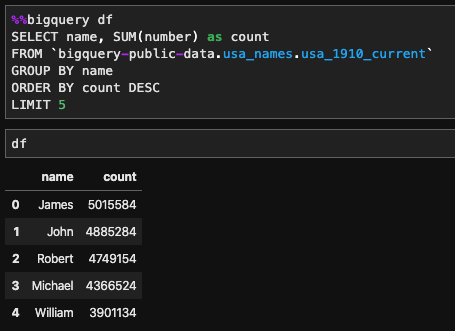
Parameters can be passed in the query using the — params flag:
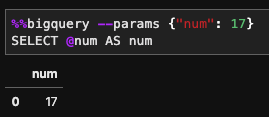
Be sure to limit the return rows for fast performance, though. Details documents of IPython Magics for BigQuery can be found here.
Using pandas_gbq library
In addition to using IPython Magics, you can use the pandas_gbq to interact with BigQuery.
Writing data back to BigQuery is also straight forward. You can run the following code:
df.to_gbq(df, table_id, project_id = project_id)
Documents for pandas_gbq can be found here.
Using Python BigQuery Client
client = bigquery.Client(project = project_id)
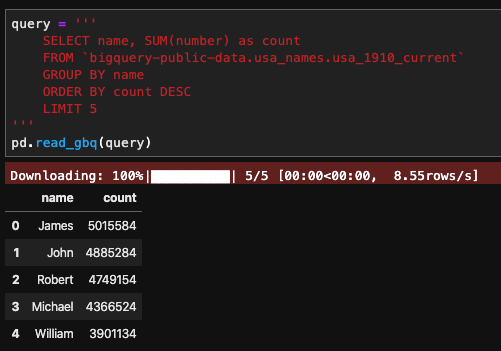
query = '''
SELECT name, SUM(number) as count
FROM `bigquery-public-data.usa_names.usa_1910_current`
GROUP BY name
ORDER BY count DESC
LIMIT 5
'''
client.query(query).result().to_dataframe()
This code yields the same result as the above methods. You can have a much more advance interaction with BigQuery using the Python client, however. Things such as create tables, define schemas, define custom functions, etc. Full documentation of the BigQuery Python client can be found here.
Conclusion
In this post, I walked through the steps of using Jupyter Notebook for a more programmatical interaction with BigQuery. Here are some of the advance things you can do when querying your data with Jupyter Notebook:
Document your code with markdown cells in Jupyter Notebook
Share your analytics as HTML or PDF
Parameterize your queries
Write unit test for your queries
Implement infrastructure as code using BigQuery Python client
Build an ETL pipeline.
Happy learning!